据外媒报道,现在一项新的技术可以让你添加、删除或编辑视频里说话者所说的文字,而这一切就像在文字处理器上编辑文本那么简单。获悉,一种新的深度伪造(deepfake)算法可以将音频和视频处理成一个新文件。

由来自斯坦福大学、马克斯普朗克信息学研究所、普林斯顿大学以及Adobe研究所的研究人员组成的研究团队开发了这样一套算法。
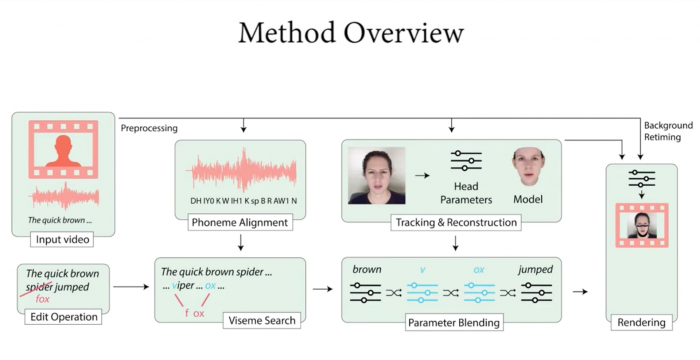
为了学习说话者的面部动作,该算法大概需要40分钟接受训练视频和说话者文字记录,所以如果想要得到好的结果就不能只用一个简短的视频。40分钟可以让算法能够精确地计算出受试者为原始脚本中的每个语音音节做出的脸型。
在此基础上,当人们编辑脚本,算法就可以创建人脸的3D模型并生成所需的新形状。一种叫做神经渲染(Neural Rendering)的机器学习技术可以用真实感纹理绘制出3D模型,使其看起来与真实物体基本没有区别。
不过研究团队也意识到了该算法在不道德领域的使用潜力。虽然世界上还没有发生一起深度造假丑闻,但不难想象,在没有受过教育的观众面前,深度造假是一种极其有效的欺骗工具。更令人担忧的是,它们的存在会让不诚实的公众人物否认或质疑真实但可能影响到他们个人形象的视频。
对此,研究团队提出了一个解决方案,即任何使用该软件的人都可以选择性地加上水印并提供完整的编辑文件,但这显然不是阻止滥用的最有效办法。
另外,该团队还建议其他研究人员开发出更好的取证技术来以确定某一视频是否被别有用心的人改过。事实上,区块链式的永久记录在这里有着一些潜力,它将允许任何一段视频可以回到其原始状态来进行比较。但这样的技术还没到位也不清楚如何在全球范围内推行。
在非指纹识别方面,许多深度学习应用已经在研究如何识别赝品等问题。通过生成对抗性网络的方法,两个网络相互竞争--一个生成一个假冒产品,另一个试图从真品中挑出假货。经过不断的学习,识别网络在识别赝品方面开始做得越来越好,而伴随越做越好,生成赝品的网络就也就必须变得越好,才能达到欺骗的目的。
因此,这些系统在自动识别假视频方面做得越好,假视频也就会变得越好。所以很显然,识别伪造视频是一个复杂而严重的问题,在未来几十年里,它几乎肯定会对新闻报道产生重大影响。
视频:
https://v.youku.com/v_show/id_XNDIzMTU2MjMyNA==.html?spm=a1z3jc.11711052.0.0&isextonly=1


